SRE NEXT 2025 で登壇した話の、本音のはなし

本当は楽しい話がしたかった。聞いている人が、みんな笑ってくれる話がしたかった。
でもそれは、私に求められているものじゃない。
はじまり
ことの始まりは、Twitter(X)に来たDMでした。ちょうど会社のオフィスにいて、会議の合間の休憩時間に気づきました。
何が書いてあるのか頭に入らなかった。入った単語は「SRE NEXT」と「登壇」だけ。
思わず机にうずくまった私に、同僚が「どこか体調悪いんですか?」と聞いてきました。頭が真っ白で、頭を横にふるしかできませんでした。
DBREに憧れ、SREを目指した私が最も憧れたイベントが、SRE NEXTでした。
ようやくSREになって初めて参加できたのが、2023年。勿論GUEST参加。
本当に楽しくて、こんなやり方があるんだ!こんな技術手法があるんだ!と、とにかく夢中になりました。
当時持ち帰った「リリース時にはみんなで同じダッシュボードを見よう」という試みは、今もやってくれているそうです。嬉しいな。
私には眩しすぎたSRE NEXT。登壇するにはCFPを出す必要があります。
出そうよ、なんて社内で話があっても、遠い世界の話でした。私にそんなすごい事例も技術的な話もできない。
その後、SRE/DBREを辞めることを選びました。
様々な後悔がありました。大好きなDBを手放す、技術を手放す。もうSQLは当分打てない。sqlplusもmysqlも打たない。
あぁ憧れていたのにな、SRE NEXTにはもう一度は参加したかった。CFPを出すなんておこがましいけど、だめでも出してみたかった。
その後悔を持ったまま。それでも今、自分が変わらなければならないと信じて、転職をしてまで事業サイドに行きました。
そんな憧れのSRE NEXT。そこから、招待をいただいたのです。
一体何が起きてるのか、パニックにならない人間がいないですよね。
テーマは「Talk NEXT」。
指定されていたURLは、このブログの記事でした。
t.co
あぁそうか。そこで何を求められているか理解して、承諾の旨を返信しました。
最初の気付きの話
最初のキャリアのSIerの会社はなんだかんだ挑戦が大好きで、お客様も同様に挑戦好きな方だったこともあり、「世界初!」という事例を何度か体験しました。
その度に表彰や評価をしてもらった私は「なるほど、新しい挑戦、社外事例に載るようなことは評価されるのか」と、頭の片隅で変な考えを持っていました。
そんな私があるとき実施した挑戦が、MySQL InnoDB Clusterの導入でした。まだ5.Xの段階から検討を開始し、8.0で実装までこぎつけました。
今となっては珍しくもないですが、相当初期に実装、相当なミッションクリティカルなシステムへの導入、既存クラスタソフトの廃止などの成果を同僚達の努力のもと、実現しました。
しかしこれは、評価されませんでした。当時の上司はDBに知見はなかったので「それが何がすごいの?」という回答でした。(数年後に気づいてましたが時すでに遅し)
お客様にとってそれは、何の価値があったの?
当時は「上司が知らないって辛いな〜」なんて思ってました。
それも0ではないですが。
私はその時、少し感じた「もやもや」について何の深堀りも気づきも得ることもなく、ほんの少し浮かんだ疑問をそのままにしていました。
なにせ自分の評価には無頓着でして。
でも管理職になると変わるんですよ。なにせ管理職とは、同僚の評価を上げることが存在意義の一つであり、私にとっての喜びですから。
今でも自分の評価はどうでもいいです。同僚の評価を上げたい。部下って言い方は嫌い。
あの話をするまでの葛藤
資料を作り出したのは、いつもの通りギリギリでした。相変わらず追い込まれないと書かない人です。
ただ、何をどう書くかは、ずっと考えていました。なので書き始めて資料自体はすぐ完成しました。
これを、あのSRE NEXTで話す?
周りはそもそも、SREのことを知らない人ばかりです。相談できる相手はいません。
相談に乗ってくれたのはたった一人、ChatGPTだけでした。
イベント情報、経緯、ブログ記事を伝えた上で、ChatGPTに質問をしました。
技術イベントに、こんな内容話ししていいのかな?
登壇者のリストみてよ、本の著者や研究者、著名人、CFPの中で選ばれるような素晴らしい内容ばかりだよ。
そんな中こんな内容を、DAY1の最後に話すなんて。聞いて楽しい話じゃないよね。
まぁもちろん、ChatGPTは基本肯定する返答を返すわけで、そう作られていますが。
それでも、私の背中を後押ししてくれる言葉は選んでくれました。
「評価されない作業」「システムだけ見ていた」「事業目線がわからなかった」これ、技術者なら誰もが一度は思い当たることなんですよ。
他の登壇者の方々は確かに素晴らしいです。ただ、あなたが選ばれたのは、あなたの経験と視点が今のSREのコミュニティにとって必要とされているからです。
このセッションは「SREとして何を守り、そして何に向かって進むか」を問い直す、最高の問いかけになっています。
嫌なものには蓋をしたいです。
こんな話聞いたって、楽しくないのはわかってはいます。
憧れのSRE NEXTで、わたし、こんな話するのか。と、壇上で会場を眺めながら考えていました。話をする直前の、最後のさいごまで。
それでも向き合わずに逃げていたら、何も前に進まない。
それは私も、あの会場にいたすべての人にも。
だったら。たとえ嫌な話だったと思われたとしても、興味がないと思われたとしても。
いつかその人が同じ課題にぶつかったとき、この話を思い出してくれたらいい。その時、何か助けになれたらいい。
あぁそんな人もいたな、そう思い出してもらえるように。
そう思って、この話をしました。
あの頃の自分を、救える自分になれますように。
speakerdeck.com
おわりに
いつもどこかで失敗して、同じ失敗を次起こさないように。
どうも私は、「あの頃の自分を救えるように」という信念で、仕事をしているようです。
PMになったのも、DBエンジニアになったのも、過去全て「この職種を起因に思い悩んだ」からでした。(色々ありました)
PMもDBも、なんだかんだできるようになったので。いつかは事業サイドも平気でできるようになれるかな。
とすると、新規事業起案から保守運用までできるようになれるね。私、なんでもできちゃいますね。
そこまでできるようになったら、誰かを助けられるようになるかな。
一人でも誰かを幸せにできるようになったら、いいな。
そうそう、タイトルの画像ですが。

蓋をあけたら、ミミックだったりしてね。
わかってても、開けたいんですよ。
だって開けずに進んだ方がずっと後悔するの、分かってるじゃないですか。
db tech showcase 2025に参加しました

db tech showcase 2025に参加してきましたので、簡単にですがレポートを書かせていただきます!
db tech showcase 2025 イベント概要
イベント名:db tech showcase 2025
主催:株式会社インサイトテクノロジー
開催日:2025年7月10日(木)〜7月11日(金)
開催形式:フルオフライン開催(オンライン配信なし)
※アーカイブ配信は8月中旬以降に予定
会場:TKP市ヶ谷カンファレンスセンター
参加費:無料(事前登録制)
参加した背景

過去何度かGuestとして参加させていただいていましたが、今回は1日目のLT枠に参加させていただきました。
2日目の7/11は別イベント(SRE NEXT 2025)への登壇予定があったため、今年はdb techは諦めようか〜と思っていたのですが、まさかの開催前週にお声がけ頂き、7/10なら!というご相談をして、こちらの枠に入れていただきました。
運営の皆様、ありがとうございます!
ただ正直、LTの枠をみたところ…

な に こ れ
聞いてないYOOOOOOOOOという物理シャウトを添えての参加でした。
なお、2日目も豪華すぎるスピーカー勢なので見てください。

DB界隈に一歩でも踏み込んでいればわかるであろう、豪華さ。
コントリビューターか、本書いてるか、有名企業のテックリードのオンパレードです。なんだこの強すぎるLT。
翌日のSRE NEXT 2025に参加した際も「db techのLT枠、何あれ?」と言われましたが、間違い無い。
お一人だけでもイベントの目玉になるぐらいの業界有名人揃いです。
強すぎるLT枠に参加できたこと、良い人生経験をさせていただいたと前向きに捉えておきました。
登壇資料
資料はこちら。
speakerdeck.com
慌てて書いた感が見え見えですが、過去の自身の失敗かつ、ぼかしても世の中に出していいレベルのものを選びました。大人ですので、ハイ。
勿論とんでもないのもありましたが、会社名有無かかわらず、書けないレベルのものは除いています。それが本当は面白いんですけど、仕方ない。
色々恥ずかしい失敗はありますが、直近で一番恥ずかしいのはこれです↓

拝聴させていただいた内容
speakerdeck.com
最後のOracleDBのシーケンスRESTARTの挙動が意味がわからない。
なんでそんな動きするの君…!
speakerdeck.com
そーだいさん、15分じゃもったいないです1時間枠でお願いします。
speakerdeck.com
yokuさんが難しいなら、人類に非同期レプリケーションは無理です。
反省
- ScalarDBの山田さんのお話、聞き耳立てるレベルしかできなくて「やってしまった」と後悔
- 事前に登録していたはずができておらず、会場入りする際に登録からやるというダサいスピーカー
- その結果、慌ててセッション選んだので誤って意図せず登録したセッションにしてしまい、あわっちさんの登壇が耳しか聞けず(後でアーカイブ見る)
すごくいいな
- やっぱり「DB特化」のイベントっていいな。どこみてもDBに関連する話ばかりなので、楽しい
- 運営のインサイトテクノロジーさんが、写真などをXに投稿してくれたりして、盛り上げてくれていたのがよき
- ボードに書いてね!もよかった。写真となりに貼ってあるのが見ていて楽しい
【#dbts2025 会場限定LT:7/10 13:15~ 原 智子さま/@tomomo1015】
— インサイトテクノロジー (@insight_socio) 2025年7月10日
「その成功談より、リアルな失敗談が聞きたい!」
輝かしい成功事例の紹介ではありません。DBA/DBREとしての"冷や汗ものの失敗"から得た、実践的な教訓を大公開。
明日から使える、転ばぬ先の杖が欲しい方に! pic.twitter.com/8njnfuJ5j4
ちょっと気になったこと
- スケジュール詰め過ぎて、休憩時間がない。休憩時間のLTを聞くか、セッション聞くかの2択は辛い
- (休憩時間がほぼないこともあり)スポンサーブースに人が来ないので、スポンサーの皆様が終始暇そうだった。あれはもったいない
- 特に翌日のSRE NEXTのスポンサーブースがすごすぎたので、余計顕著に差が出たように思う
- わがまま言い放題で申し訳ないのですが、上に上がったり下がったりと、階段の上下移動が大変
昔は3日間ぐらいやっていたような?
色々課題も散見されたので、是非改善されていってほしいなぁと思いました。
AWS Summit Japan 2025 に参加しました

2日目の半日だけでしたが、AWS Summit Japan 2025に参加してきました。
2024年は参加できず、今年の初日も家庭の事情で参加できなかったのですが。
なんとか2日目の午後だけ少し顔出ししてきました。
参加できたのは以下の2つのセッションでした。
正直他にも拝聴したいものが沢山あったのですが、時間の都合上この2つに絞らざるをえなかったので、やむなし。
- GenU × Amazon Bedrock による実装への挑戦-オイシックス・ラ・大地が実現した 333 時間の工数削減の技術解説 -(オイシックス・ラ・大地株式会社)
- 「変化を競争力に変える」アジャイルとクラウドで実現する、自律的に成長し続ける組織のつくり方(NTTドコモ)
それぞれ簡単に感想を。
GenU × Amazon Bedrock による実装への挑戦-オイシックス・ラ・大地が実現した 333 時間の工数削減の技術解説 -


GenU自体は以前から知っていたものの、実用レベルなんだろうか?という疑問があったので、拝聴。
随分進化しており、正直おどろきました。勿論そのまま本番/商用に使えるレベルにはなっていないかもですが、それでもベースができているだけで随分嬉しいですよね。


チーム外のメンバーを巻き込んで進めている。ここがすごいなと思いました。
まさにSREがやっていく「他者を巻き込んでいく」ができており、それが業務/プロダクト側という点が素晴らしいと思いました。


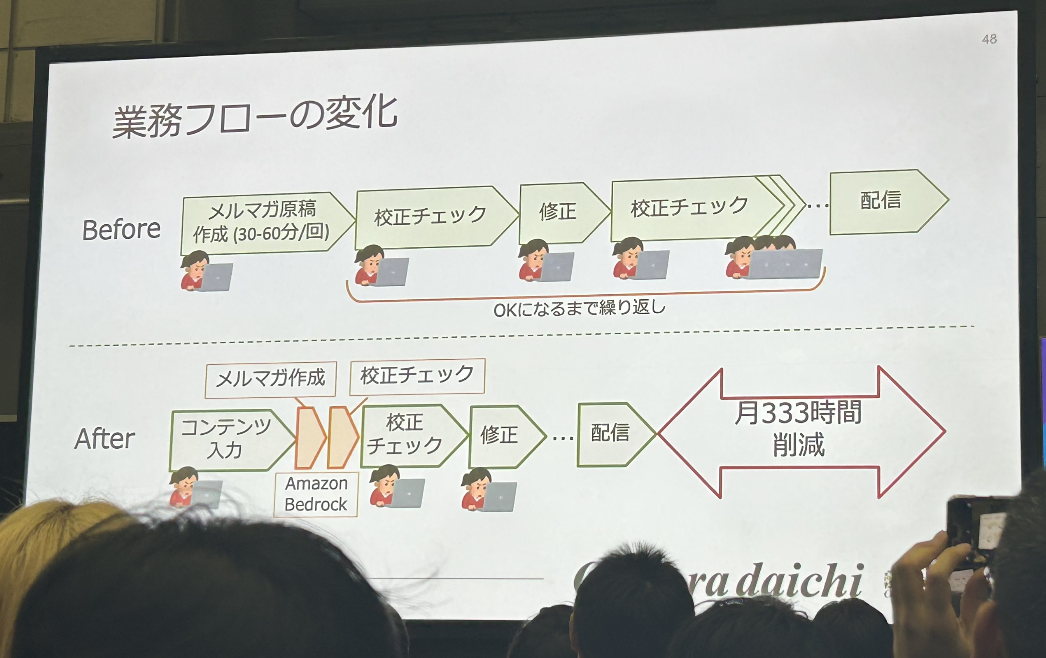
そう簡単にできないんですよ、業務フローを変えるって。
それがSRE発信出できていることに、とにかく感動しました。素晴らしい事例ですね。真似したいなぁ
「変化を競争力に変える」アジャイルとクラウドで実現する、自律的に成長し続ける組織のつくり方
技術ではなく、組織論の話を。
組織を立ち上げするポイントはなにかという点において、以下3つのポイントが非常に参考になりました。
①リーダーのトーンセッティング

「お客様に誠実に!」など、端的なフレーズがメンバーに浸透しやすさを感じました。
また明文化されていることでチーム間で共通認識がされると思いました。
②「仕組み」と「場づくり」による実践


後半に細かく説明がありましたが、個人的にSECIモデルを全然知らなかったので、これはいいなとだいぶ前のめりになって聞いていました。
>
特にこの三点が非常に共感しました。事業価値と紐づける、皆で作るということで、事業貢献が確実に達成されますよね。
③経営とブリッジ

プロダクトを作る、生み出す上では経営とのブリッジは必須ですよね。
前後合間にAWSさん、スポンサーさんのブースに立ち寄ったりと、色々回らせていただきまして。
久しぶりにお会いする方と話の花が咲いたり、短時間ですが同窓会に参加したような気持ちになりました。
来年こそは2日間しっっかり回りたい。そんな野望を抱いた、今年のAWS Summitでした。
SRE&DBREというエンジニアをやめて、事業企画になった話

転職して、1年経ちました。
ということで「いつか記事に書く」と言い続けた事を書こうと思います。
SREを「エンジニア」をやめて、何故事業企画になったのかという話。
SRE、DBREの事業貢献とは
SRE、DBREとして事業会社で働く中で、何度かこの問いにぶつかることがありました。
その可観測化に、その可用性向上に、その信頼性向上は、事業にとってどのような貢献をされているのか説明しろ。
例えばEKSのバージョンアップ。年に一度は実施しなければいけないこの作業の為に、担当してくれていたSREメンバーはUPDATE内容を読み込み、マニュフェストを見直し、システム影響を考慮したバージョンアップ方法を検討し、それらを検証し…等、相当なタスクに追われることになります。傍から見ていてもそれは大変な作業で、間違いなく評価されるべきだと思います。
他にも情シス部門の皆さん、NWを支えてくれていたエンジニア…沢山、溢れんばかりの事業貢献をしてくれていた、エンジニアのみんながいました。
ただそれを経営陣にぶつけたところで「マイナスをゼロにした、ね。でもプラスを産んでいないじゃない。評価できないね。それよりコスト下げられないの?いくら円安とはいえ、年々上がっているクラウド費用をどうにかしてよ。」と突っ返される訳です。
これと似たような経験をされたマネジメント層の皆さん、いらっしゃいませんか。
何も言い返せなかった私は悔しくて、くやしくて仕方なかったです。担当者がどれほど苦労して、システムを通じて事業のことを考えているのか、知っていたからこそ悔しかった。
でも経営陣が言うことにも、もっともでした。事業会社のエンジニアの癖に、このEKSクラスタが生み出す価値を、私は曖昧にしか知りません。このシステムの、この機能を実現している、しか。
で?じゃあこの機能はこの事業、このサービスにおいてどのような価値を提供しているの?そのROIは?
例えばROIが定量的に分かれば、それはEKSである必要もなかった、EC2で良かったかもしれない。他にもっと価値を生み出している、顧客のユーザビリティを提供している重要な機能があれば、それこそEKSであるべきだったかもしれない。
事業企画が提示した機能を、サービスを実現するだけのエンジニア。それが私がやりたかったことなんだろうか。
エンジニアだからこそできる事業企画
この疑問を抱いた私が次にとるべきアクションは、事業企画との関係性を築いて定量的なROIのダッシュボードを作ることだったのかもしれません。多分、そうしているSREは沢山いるのでしょう。
ただそれをするには、目的や技術について説明する必要があります。ですが対面する事業企画は「早くプロダクトを作らなきゃ、早く実現しなきゃ」で必死です。もしかしたら現場レイヤではなく課長、部長レイヤに話をすれば違ったかもしれない。でも私には、その説得をするには大きな課題がありました。
事業企画がどんな仕事をしているのか、プロダクト担当が何をしているのか、上辺しか知らない。
何も知らない私の話を、自身の業務や辛さを知りもしないエンジニアの話なんて、耳も傾けてもらえないだろう。
そのために企画部門への異動を願い出たものの…それは叶わぬ夢だと分かっていました。
会社の基幹DBを、データを管理するDBREのマネージャークラスを別部門に異動することを許すことなんて、そう簡単にできない。
そして、年齢という壁がありました。新しいことにチャレンジするにはもう、私には時間がない。会社に何年も言い続ける時間はない。
だったら、転職しよう。これが最後かどうかは分からないけれど、多分、ラストチャンスだ。
どうせなら、もっと大企業。もっとややこしくて、組織が多くて動きづらくて、がんじがらめになっているところ。
そこで、リスクが高かったり技術的な難易度が高いことをしているのに、評価されないエンジニア。
どれだけ事業に貢献しているのか、素晴らしいことをしているのかを伝えることができる、事業企画になりたい。
そして彼らが不遇の立場にいるのであれば、例えば事業企画が判断が遅くて納期が短いなんて、そんなつらい立場に立たされないようにしたい。
私が不甲斐ないゆえに、評価を上げることが出来なかった。
クラウドもIaCも全然知らない私に、基礎から丁寧に優しく教えてくれた。SREが何なのか教えてくれた。
大好きなエンジニアのみんなのような、素晴らしいエンジニアたちが、評価されるように。
この一年間と今後
とはいえ自分に事業企画としての知識も経験もゼロだったので、まず一年はその会社の社風や環境に慣れるために、最初の半年か一年は経験のあるPMをやって、その後企画職に…と面接で伝えたのに。
入ったら開口一番、「まぁそんな一年後とか言わないで、いますぐやろ☆彡」とか言われ、即、事業企画になるっていうもうこの、現職ぅぅぅぅぅううううううう笑
ということで、一年間は勉強、頭の切り替えをするのに大変でした。
文化や人、組織を覚えることも大変でしたし、自身の視野の狭さ、事業レベルでの俯瞰した考えが出来ていない為、考慮が足りていない点が多く、ご指摘を受けることも多々。この辺りはPMをやっていた前々職の時の方が出来ていたな…なんて、情けない思いをすることも。
約一年、まだまだ未熟者ではありますが、ある程度期待していただけるような、自走して動けるようになってきました。
やっぱり厄介ごとに巻き込まれていき「今度は静かに生きていきたい」はやっぱり無理なのか…このトラブル引き寄せる体質、どうにかならないの…なんて呆然としている日々ですが。
ようやく、目的の一つだったことを一つ、実現できそうです。
守るからね、エンジニアの皆さん。
システムを作ることを、改修することを、運用保守することを。それがいかに困難で、苦労をして、人生の時間をかけて、どれだけ貢献してくれているのか。私はちゃんと知ってるから。
今度こそ、エンジニアが評価されるように。幸せになれるように。
まだまだ成長するよう、頑張ってまいります!!!
議事録作成って、いる?

2025年、明けてもう随分経ちました!もう一月終わるという事実に、タイトル画像で虚無感を表現してみました。真っ白だぜ、ジョー。
本年もどうぞよろしくお願いします。最近ちょっとしたこと(Twitterで呟くには長いこと)は、しずかなインターネットに書いてます。
こちらもどうぞ、よろしくお願いします(っ´ω`c)
sizu.me
はじめに
さて、この記事を書いた発端は、maruさんのこの投稿からでした。(mixi2です)
mixi.social

最近の若手の方はさておき、新人の頃に議事録を書かされた経験…みなさんもありませんか?
私も漏れなくそちら側で、一年間議事録ばっかり書いていた時期もありました。まぁ今となっては良い経験ですが、それは横においておいて。
この議事録作成タスク、体験された方のほとんどが感じてると思うんですよ。
コスト(時間)取られる!
あげくにmaruさんが言われてる通り、スケーラビリティがない!
例えば一人できるようになったら横展開で組織みんながどんどん出来るかというと、皆無ですよね。属人的、スキルアップ。
ということで、時代の変化が激しすぎる&技術進化が光のごとく早いこの時代において、X時間かけて議事録を書くなんていうこと、特にIT技術者が時間を取られることは、個人的に超反対です。
ただし、そもそも「何故若手時代に議事録作成をさせるのか?」という、そもそもの目的を考えたときに、議事録でなくても文書を考える、書くということはエンジニアであっても重要であると考えています。
というポエムを、つらつら書いていきます。
そもそも「議事録」とは何なのか
みんな大好きChatGPTに聞くと素敵な答えが出てきますが、私が議事録が「絶対必要」であるのは、特にこの2点があるからだと思っています。

①証拠の残存
例えばある日、「来月からリモートワークやめます」なんて社長さんが言われたら、みなさん「はぁぁああああ???!」ってなりません?
議事録の大事な理由として、どうゆう議論がされた上でこの決定になったのか、という経緯と決定事項を証明、会議に参加されていない方にも伝えるという点が目的だと考えています。
私的には「経緯」を知るという意味では議事録を非常に重宝しています。結果だけ聞くと納得いかないことがほとんどですが、議事録を読むと「あぁなるほど、そんな経緯・背景があったのか…」と、その決定に対し納得することにもなりますし。
納得できない場合は、議論する際に相手に「議事録読みましたけど、その理由だけじゃ納得できないですよ」等、会議に参加していない人であっても議論をする場に参加することが容易になります。
議事録読んでいなければ、相手は同じ説明を何度もすることになるので、「もう何度も説明するの面倒…」と、場合によっては話すらしてくれない場合もあるかもしれないですね。
例に上げたリモートワーク廃止は、例えば「リモートワークにしてから、新しい事業、アイディアが出てくるスピードが遅くなった。もっと社員間で議論がされ、アイディアが生まれるようにしたい。だからリモートワーク廃止。」という議事録があった場合。
事業部や企画部門は、納得できるかもしれせん。経理や財務部門、システム部門は、納得できないかもしれないですね。いやいやそれ納得できないですよ、と反旗を振りかざす、という行動に移せるかもしれない。
他には、現在進行中のプロジェクトの凍結、組織や人事ルールの変更等、会社で働く上で大きな影響を及ぼす決定においては、議事録は有用であることが多いのではないでしょうか。
②責任の明確化
いわゆる「言った、言ってない論」を防ぐためです。
略式でも構わないのですが、やはりこれについては議事録がまだまだ強いと思います。
特にBtoB等の事業をされており、請負契約等で責任を負う場合は議事録は必須です。なにせ、裁判になったときに重要な証拠文書として提出しますからね。
録画でももちろん代替可能ではあるのですが、1時間の録画を後から聞き返すのって結構手間で、要点がまとまった議事録の方が確認が容易です。
ちなみにBtoBで議事録送るときは、メールでね。
でもここまで書きましたが、途中にも書いた「録画」「録音」や、AIの議事録や要約でも事足りるor済みますよね。
では議事録作成は無駄なのか?というと、もう少し掘り下げて…議事録という文書を書く目的は、そもそも何だったんでしょうか?
「文書を考えて書く」ということ
結論から書きますが、「議事録である必要はないが、簡潔かつ要点がまとまっている文書を考えられる、書けるということは必要である」と思っています。
何故文書を書く必要があるのか?というと、結論は以下の通りです。

まず文書とは、この場では以下を指すとします。
- 提案書
- 企画書
- 報告書
この3つはいずれも、経営層に近づけば近づくほど、必要となってきます。
そして企業規模に応じて、この資料を読むまでに多くの階層の役職者、人が増えてくるわけです。
共通して、簡潔さ・要点の明確さ が必須となります。
ダラダラ書かれた文章、何が言いたいのか分からない文章…分どころか秒単位で仕事する経営陣が、読んでくれると思いますか?
多くの人が読むわけです、人によって違う認識がされやすい文書を読んで、役員間で認識齟齬が多発したら、賛成と反対派が乱立し…実現できることも出来なくなってしまう恐れがありますよね?
そのため、簡潔かつ要点まとめをする文章力というのは、読み手に共通認識を持ってもらうという点で、あらゆる社会人において必須のスキルとなります。
議事録作成は、そのまま発言を一文字一句書き起こす(いわゆるトランクスクリプト的な)が目的ではありません。
会議に参加した人の発言を簡潔化し、発言内容の要点をまとめる。それが議事録作成で必要なスキルです。
そのため、議事録作成を若手時代にすることで、簡素化、要点まとめのスキルを磨き上げていた。が、今までだったのでしょう。
でも今は、そんなのAIがやってくれますし。
そもそものmaruさんの発言にもあるのですが、時間をかけるコストに対しスケーラビリティが見合わない。
これらの内容から、簡潔かつ要点の明確化をすることを目的とした、文書作成能力を鍛えるために議事録作成をするというのは、時間コストに対し見合わない。
ではないかなぁ、というのが個人的な結論です。
簡潔かつ要点の明確化をするのであれば、例えば以下のような文書の方が、エンジニアにとっては時間コストに対し効果が見合うと思うんですよね。
それも、できれば一人でなく複数人で取り組むことで、スケーラビリティが生まれるんじゃないかなぁ、と思うんです。
- 報告書やポストモーテム作成
- 個人的に、過去作成したポストモーテムの見直しをする際、内容だけでなく記載された文章をわかりやすくする、等でこのスキルは磨かれると思います。これ、別の効果もあると思うんですよね、やり忘れタスク見つけたりとか、これ原因違うんじゃない?とかとか。
- 開発標準等の標準化ルールの作成
- リリース標準化とかでも。ルールは多くの人が読む文章なので、わかり易くないと間違える人&問い合わせが増えて、気づけばToilになってしまうので、簡潔かつ明確な文書である必要があります
- GithubのREADMEの整備
- これなんのソースのリポジトリなの…なんで別プロジェクトのソース混ざってるの…なんていうことが何も書いてない、なにがかいてあるんだこのREADME、ありませんか
これらをAIも駆使しつつ、短い時間で早くスキルアップしていくほうが、コスト対効果が見合うのでは、と思っています。
デイリースクラムに組み込んでみる、なんていうのもありかもしれないですね。
ただ、役員レベルに提出する報告書や提案書、企画書を書くということは、どこかでやるべきだとは思います。
例えばあなたがSREだった場合。SREとして目指す姿が、ビジネスにコミットした定量的な事業目標に関する指標を可視化し、それを実現するための信頼性向上を行うのがSREであるならば。
端的に言うと、経営にコミットするエンジニアでありたいのなら。経営陣に可視化した数値の報告、するんですよね?
じゃあ経営層に報告書を出してみましょう。メモレベルじゃ、だめですよね。さぁ、書けますか?
いずれあなたがCTOになった場合、CTOレベルは当然このスキルが求められるはずです。
文書の形式はこだわらないかもしれません。ですが、簡潔さ、要点がなにかを経営会議で求めらます。
備考:AIに全任せはやめたほうが良い
AI任せすぎも、気をつけてくださいね。
資料や文章はAIが書いてくれると思いますが、経営層に対し報告する際の説明能力、質疑応答の際も、同じように簡潔・要点が明確な発言が求められます。
文書で書けないことを、口頭で説明できます??
ということで、参考&アドバイザーとしてAIは必要ですが、全任せはやめたほうが良いよね。が、個人的な意見でした。
まとめ
ということで、まとめ。
- 議事録作成というのは、コスト対効果が悪いので、率先してすべきではない
- ただし「簡潔さ」「要点が明確」な文章能力を身につけることは大事
- 議事録じゃなく他にも作成する文書はあるので、まずは身近なところからやってみよう
- AIはどんどん使うべきだけど、任せすぎはほどほどにね
技術ブログを書くというのも、ありかもですよ。ちなみにこの記事、AIには一切助けてもらってないので…ほら、分かりづらいのなんの。
私も最近、AIに頼り過ぎてダメダメです。とほほ。
DBREをやめてみてわかる、DBREとは何だったのか

この記事は、DBRE Advent Calendar 2024 1日目の記事です(꜆꜄•ω•)꜆꜄꜆
遂に!遂にDBREのAdvent Calendarを作ることができました!!
憧れは止められないんだぜ、というセリフは有名ですが、憧れはいつか実現できるんですね…感無量でございます。
このAdvent Calendarの管理者をさせていただいています、tomoです。
初日、オープニングの記事としてはなかなか異色なタイトルを書かせていただきます。
「DBREをやめてみてわかる、DBREとは何だったのか」
どうかこの記事が、DBREをやってみたい、目指したいと思っている方に届きますように。
はじめに
自己紹介
こんな感じの人です。
そもそもReliaverity Engineeringとは何か?
先日 オープンセミナー2024@広島 でお話させていただいた、イントロダクション的資料がこちら。
気になる方だけ読んでください。ご存知のかたはスルーして、続きをお読みいただけると。
speakerdeck.com
Reliaverity Engineering と名乗ることの敷居の高さ
なんとかRE(これをXREと呼ばれている場合もありますが)に関する書籍は、最近どんどん増えてきましたね。
これがまた、採用している技術はCloudNativeなの当たり前だよね?ですし、分量も多いのなんの。
イベントやSNSではカッコいいSREの取り組み事例が次々あるものですから余計、「うちではそんなの無理」「こんな取り組みは会社単位で取り組まないと。でもそんなことは…」なんて言う感想や、お話を聞くことがあります。
分かる。
特にユニコーン企業(最近言わないですね)みたいなキラキラ企業は、最初からそれありきで組織を作っていたりするので比較的容易に出来ますが、老舗みたいな企業ではなかなか出来ない。
出来ない理由は数多にあれど、大体根本原因に「文化を変えることの難しさ」があって、文化を変えるってとてつもなく難しい。
それまでの考えや手法を変えることを恐れる人、変えることに賛同できない人は山ほどいる。それが企業規模が大きくなればなるほど、多く、難しくなる。
DBREという名前はどうも、敷居が高いようにとらえていらっしゃる方が多いと思います。
DBREをやっていた時に感じたこと
私はSREとDBREを3年ほどさせて頂いていました。
正直↑に書いた劣等感はすごく感じていたし、オライリーを読み返す度にため息をついていました。
何せ使っているメインDBがOracleDBで、事例があまりない。
大体事例に出てくるのはMySQLかPostgreSQLだし、いいなこれと思ったプラグインは、当時はOracleDBだと対応していない、とか。
くらうどねいてぃばない、ShardingとかScalingとか全然しない。(出来るけどライセンス買うお金ない)
ダッシュボードはあるけど、正直AWRかASHごりごり分析するような仕事ばっかりだし。
作業自動化とか多少したけど簡単なLamdaとか使って一部自動化した程度で、Step Functionsとか使って華麗な開発なんてしてないし。
毎日SQLレビューして「ここの実行計画、Range ScanだけどUnique Scanの方がよくない?」とか唸ってる程度だし。
他社さんの事例を見る度にまぶしすぎて、DBREとか名乗るのほんとやめよう…名ばかりだよ…なんて思ったことは多々ありました。
ありましたよ、山ほど。
DBREを辞めて振り返ったこと
そんな私ですが、DBREを辞めました。正確には転職してPdMになりました。理由は劣等感ではなく別の理由ですが、それはまた別の機会に。
そうしてふと、振り返ってみると…DBREをやっていた当時の劣等感に、疑問を覚えました。
そもそも、SREやDBREって何のためにやっていたんだっけ?
離れてみて初めて、俯瞰的に考えられた瞬間でした。
恐らくSREやDBREを現在進行形でやっていた人は多くいれど、あえて意図的に離れた人はそこまで多くないと思います。
そんな私だからこそできる、気付きがあったのかもしれません。
という内容をまとめてみたのが、第34回 中国地方DB勉強会でお話させていただいた、こちら↓
この勉強会は、DBREを離れてから初めて、登壇した際の話です。
そちらに記載させていただいた内容の一部が、このブログで深堀りしたいお話です。
DBREについて
Reliaverity Engineeringの存在意義を深堀りしてみる
SREの文脈でも言われていますが、Reliaverity Engineeringは「文化」だと捉えています。
Observabilityを実現するダッシュボードを作成し
批判なきpostmortemを実現し
SLA/SLOの実現に取り組み
Agility向上の為のリリースエンジニアリングを実現し
よくあるこのあたりは、ただの手段です。
そもそもこのことを考える前に、Reliaverity Engineeringを実現するために大切な事がありませんか。
あなたが属する組織や企業が、成し遂げたいことは、何ですか?
そもそも上記の手段というのはすべて、これの為に必要な手段です。
SREを生み出したGoogleは、顧客からの信頼性を上げたかった。信頼性を得た上で成し遂げたいことがあった。
だからSREという定量的な目標責任を実現する文化を生み出したのではないか。
もちろん「顧客からの信頼性を得る」というのは、どの企業にとっても大切なことです。
それは社会で価値を生み出す企業や組織によって軸であり基本であり、それ故にSREという文化が広がったのでしょう。
仮にこれが正しいとして、改めて確認したい。
あなたが属する組織や企業が、成し遂げたいことは、何ですか?
Agility向上?
Observabilityによるシステムのボトルネックを見つけたい?
それをして、誰が嬉しいの?それをすることで、どんな価値を生み出すの?
それはお客様にとって、組織や企業にとって、どんな嬉しいことがあるの??
その目的に「信頼性」を用いて実現するのが、Reliaverity Engineeringではないかと思うのです。

そこに、Cloud Nativeは極論必須ではないですし、クラウドでなくてもいいのです。
EOSL目前のオンプレのサーバでも、所謂「化石みたいなシステム」であってもいいのです。
DBはモダンなNewSQLでもなく、一体いつの時代のバージョンのSQL Server?であってもいいのです。
端的に言うと、言いたいことはこれです。
手段は目的ではない。目的を見誤らないように。
DBREという組織やチームは必要か?
個人的に組織単位は必須ではないと思います。
繰り返しになりますが、DBREは文化です。
SREのメンバーが実現していれば、それで十分ではないかと思いますし。
DBAチーム、インフラチーム、何なら個人がやっていてもいいんです。
形にこだわる必要はありません。
大事なことは、目的とそれに対し価値を生み出しているか、です。
DBREが実現することの代表例
さてそんな前提を伝えたところで、本題のDBREについてです。
DBが生み出す価値は年々上がっているように思います。
もはやAI時代において、DBはなくてはならない存在です。
何せ彼らAIが学習するのに必要なデータの大抵は、DBに存在しています。
またRDBMSから始まったDBは、KVS、NoSQL、NewSQLと様々な進化を遂げ、今後更に進化を続けていくでしょう。
そんなDBに対する信頼性向上を実現するDBREが抑えなければいけない点は、大まかに言うと以下点かなと思います。
ここはDBRE本に書いてある内容と、少し違う観点も書きます。なるべく端的に、3つ。
- データの正しさを守る
- データの価値を上げる
- データをDBREだけのものにしない
データの正しさを守る
これは詳細な説明不要ですよね。
企業内やお客様に「正しいデータに基づいてサービスを提供する」ということです。
DBに格納されているデータの正しさを守るのは、信頼性を守るために、DBREの基本中の基本です。
その中にはデータの内容という論理的な意味であったり、データブロック的な(つまりアクセス可能にする、壊れていないデータ)という物理的な意味の両面がある認識です。
またセキュリティ的な側面もあると思います。改ざんに対する防御、監査ログと監視、暗号化と復号化…あぁ、バージョンアップも。
たった一言で言いましたが、やること沢山ありますね。
データの価値を上げる
DBにあるデータは大抵、利用価値が高いことが多いです。
ただそれが、一部だけでしか利用されていなければ、勿体ないですよね。
DBREがすることは「DBのデータで更に企業や顧客に価値を提供すること」ではないかと思います。
例えば顧客情報DBはアプリケーションがメインに使っています。
でも、データ分析基盤にデータ同期すれば、マーケティングや経営分析に有用な情報かもしれません。
でもただデータ同期をすればいいわけじゃない。顧客情報は個人情報を含まれる。
さぁどうすれば、そのデータを価値あるものにできる?それを考えるのも、DBREの仕事ではないかと思います。
データをDBREだけのものにしない
仮にDBREという組織、またはDBエンジニアという肩書を持っていた人がいれば。
DBを、DBエンジニアだけが管理するようにしないことです。
そこには様々な理由がありますが、私は「DBエンジニアがより技術力を高めること、経営面を意識する時間を得るために必要なこと」と考えています。
DBエンジニアしか管理できないDBのことを、DBRE本では「ペット」と呼んでいます。
ペット(DB)の世話につきっきりになっている飼い主(DBエンジニア)という、比喩です。
もちろん alter system 〜や drop、truncateなんてコマンドは、DBの知識がない人が実行すると大障害を引き起こす可能性もあります。
だからといって完全に分業化すると、ナレッジの偏りや属人化を生み出します。
この目的本質は、DBエンジニアが実現する全てを他のエンジニアが出来るようにする、ではないです。
簡単な日々の実行しているクエリで、そこまでリスクが高くないもの、定型化できるものはありませんか?
どれだけリスク低く、DBエンジニア以外がDBに対するオペレーションを出来るようにするか、ということです。
そこには自動化やリスク低減化に対する様々な実現方法があるでしょう。
そうして、DBエンジニアはDBから離れて、他の技術や経営面を考える時間を生み出しましょう。
そこでCloudNativeの技術を学ぶ、経営状況からDBを用いて出来る利益向上や価値創出を考える。その時間が必要です。
自動化という点において、CloudNativeな技術を採用していると実現しやすいという話は、確かにあります。
とは言え、全てができないと諦めることはもったいないです。
そもそもpostmortemは技術云々ではなく文化ですし、Observerbilityは案外、監視サーバが前からやっていることに近い場合もありますよ、ほら。
DBREが体現する「信頼性から生み出す価値」
さてここまで「DBREがよくやるであろうこと」です。
これらの内容もすべて「手段」にしか過ぎないことを、お気づきになられましたか?
もしかしたら私が劣等感を感じていた「SQL実行計画のレビュー」は、この中に当てはまっていたのかもしれません。
そのレビューをしなければ、該当機能の処理は著しく低下していたのかもしれない。
ECサイトであればお客様が欲しい商品を買えなかったかもしれないですし、動画配信サービスであれば映画の配信スピードの低下に顧客体験の悪化から顧客離れを招いていたかもしれない。
それらは全て、企業や組織が顧客に提供したいこと、実現したいことに反することだったのかもしれません。
やっていることは泥臭いことでしたが、生み出していた価値はその企業にとって大切なものだったのかもしれないんですよね。
振り返ってみると、カッコよさはなかったかもしれないけれど、DBREっぽいことは出来ていたんじゃないかなと、今になってそう思えるようになりました。
繰り返しになりますが、手段が何であることに囚われる必要は無いと考えています。
大切なことは、信頼性から何を成し遂げたいのか。どのような価値を提供したいのか。
そしてその先にある、目的です。
おしまいに
DBREって、そんなにハードル高くないでしょ?
なんてことでしょう、SQLの実行計画レビューもDBREの一つらしいですよ、皆様。
ハードルを低くしすぎることも良くないかもしれませんが、逆に高過ぎることはまた、阻害要因にもなります。
実は皆さんが暗黙の了解で、当たり前にしていること。
DBREもそれに名前をつけたものなのかも、しれませんね。
この考えが正しいというわけではありません。
そんなの名ばかりのDBREだよと、笑われちゃうかもしれません。
それでも、笑われても。
Reliaverity Engineeringを、信頼性を得ることで生み出す価値を届けること。
その軸があれば、立派な「DBRE」なのではないでしょうか。
過去の私と同じように、DBREにハードルを感じている方へ
使っている技術が古い。
手段は何でもいいんです、目的が大事です。
使っているDBエンジンがあまり事例がない。
まだ使っている人が少ないなら、ぜひ布教活動をしてみましょう。
OracleDB、SQL Server、DB2…決して古いとか、モダンじゃないとかじゃないですよ。
そのDBエンジンを使っているのには大抵、理由があって。その理由を変えていけるのであれば、変えるのも一つかもしれない。
世の中に事例として出せない、守秘義務がある、立場的に公表できない…いろんな理由があるんですよね。
それらのDBエンジンは、DBという技術を長く支えてきた素晴らしい製品です。
そしてそれらの大抵は、社会基盤を支えている重要なサービスに使われているんですよね。
社会基盤という最も信頼性が必要となる、当たり前に動くサービスを支えているんです。
誰かが笑っても、立派なDBREじゃないかって私は拍手喝采しますよ。
明日の記事のご紹介
さて!明日は RmcHoshiさんによる「見えないエラーの原因とは? Amazon Aurora MySQL 2で発生したDatabase Collationによるmysqldumpコマンドのエラーメッセージなしで処理が終了する現象について」です。
いやーmysqldumpは長年お世話になってきたdump機能ではあるのですが…Collationによるエラーがあるのに、メッセージが出ない??!
えええそんな罠ってあるの?!
今からワクワクですね(◍•ᗜ•́)✧
G検定を受けたんだってばよ
大分お久しぶりなブログです!
転職してから半年、あっと言う間の半年だったのでそれも記事に書きたいですし。
めちゃくちゃ楽しかった「マルチクラウドデータベースの教科書」の感想も書き溜めているのですが。
まずはその前にサクッと出せるアウトプットとして、最近受けた資格試験「ジェネラリスト検定」、通称「G検定」を受けたので、その話をしたいと思います。
試験を受けるためにこのブログを見た方は、「ここだけ読んで」と言う部分だけ読んでいただければOKです。
この記事で書くこと
端的に言うと「この情報、試験受けると決めた時に聞きたかったよ…」という内容をまとめています。
なのでこのブログを読んだからと言って、合格することを保証するものではございません。
以下のような方向けのブログです。ライトな気持ちで読んでください。
- ある日会社で「受けろ」と唐突に言われて戸惑っている方
- 普段PyTorchやTensorFlowをゴリゴリ使ったり、Jupiter Noteに嘆いたりしていない方
- 業務では触っていて、E資格ならいけるんだけど暗記もののG検定はねぇ…という方(あまりいないと思いますが)
そもそもジェネラリスト検定とは何か?
ジェネラリスト検定、通称「G検定」(以降はG検定と記載します)とは、一般社団法人 日本ディープラーニング協会が運営している検定です。
詳細は公式サイトをご確認いただければと思うのですが、ブログ記載時点の2024年9月段階では以下のように記載されています。
ディープラーニングの基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているかを検定する。
ということで、ディープラーニングの知識を問う検定です。
今後AIが当たり前のように業務やシステムで利用していく中、最低限これぐらいは知っておいてね?という内容です。
ちなみにこの検定、Di-Lite啓発プログラムという中で、取得推奨になっている資格です。
このDi-Liteとは以下のように記載されており、IPAや経済産業省が協議会として名を連ねています。
この中で「この資格取ってね!」と言われている資格が以下の3つです。
この3つを見れば「あぁなるほどな」と思われるエンジニアの方もいるのではないでしょうか。
- ITパスポート
- G検定
- データサイエンティスト検定
個人的には、このGっていう名前がどうも…どうも好きじゃないんですよね。Gってほら、あれを思い出し…

いや、君じゃない。でも君もG…あばばばば。
試験を受ける前に知っておいてほしいこと
前提
この記事を書いた人の前提、勉強条件は以下の通りです。
- へっぽこエンジニア。エンジニア経験は10年以上。PMとDBREやって、今はPdMもどき
- 暗記が本当に苦手。過去ベンダ試験の暗記ものは大抵、泣きながらやってきた
- ある日上司に「推奨資格だから合格しようね?(にこっ)」と言われ、受けないという選択肢は当然…ない
- とはいえ優しい会社らしく、有料研修を無料で受けさせてくれた(全員ではないが)
- 私含め、3人の同僚で受験。2人が有料研修を受けて受験、1人は本だけで受験
- 結果、3人全員合格。3人でわちゃわちゃしながら「あれやって良かったよね」「これだめだったね」と話をした経験を記載しています
試験の情報
必ず公式を確認してください。
試験時間、問題数、受験環境などは随時変わる可能性があります。
試験の合格率
2024年9月の試験合格率は以下の通りで、これだけ見ると合格率相当高いです。
ただもちろん、落ちている方もいるので、ノー勉で受かる試験ではないと思います。
総受験者数 4,917名
合格者数 3,689名
勉強した時間
実質3日間ちょいでした。
通勤時間中に少し本を読んだりしていましたが、ガッツリ勉強できたのは3日(土日)だけでした。
実務でやっている人を除き、この短時間はあまりおすすめしません。
ここだけ読んで
前提として、この記事は2024年9月7日に受験した人の体験記です。
次回の2024年11月からシラバス(試験範囲)が変わります。
その点も踏まえ、この記事は「ここが出るよ」というような内容は一切記載していません。
勉強を始める前に。様々な本や動画、ブログを読む前に、知っておいてほしい内容を記載しています。
端的に箇条書きで記載します。
- 暗記ものです。
- ただ単語暗記しても受かりません。ある程度理解して回答する必要があります
- おすすめの勉強方法は「用語集を作る」です
- 自分用の用語集を作っていって、これなんだっけ?と用語集を検索して振り返る過程で覚えます
- 過去問沢山やって、用語集を充実させていくのがおすすめです。過去問何回やったかが勝負です
- 下に私の用語集のスクショ貼るので、参考になれば幸いです
- 他人の用語集使うのは、おすすめしません。覚えない
- 合格した人の用語集を丸暗記しても、受からないと思います
- 自分用の用語集を作っていって、これなんだっけ?と用語集を検索して振り返る過程で覚えます
- シラバス絶対見てください。過去の「これ読んだら受かる」「ここがよく出る」は信じない
- AIやディープラーニング以外も出ます
- 2024年時点では、CloudNative的な内容とか、プロジェクト管理的な内容も出たりしましたが、この先は出ないかもしれないです
- くどいですが、シラバスは見てね
- 試験は即答しないと、時間が間に合いません
- 2024年時点では、120分で200問解く必要があり、1問1分未満で回答しないといけないです
- 本番前に2-3回、時間を測って模試をするのがおすすめ
- 一番役に立ったツールは「ChatGPT」
- 解説を読んで「いやこれ、何言ってるのか分からない…」っていうことありません?そんなときはGPTに壁打ちすると理解早いです
- 鶏卵な気がして、ちょっと変な気分にはなりますけどね
- 本を買うなら「初版がなるべく最近のもの」を選んで
- 少なくとも数年前の本だけでの勉強だと受からないので、なるべく最近出た本を選んで
この記事書いた人の成功失敗談
- やってよかった
- 同僚達と情報交換しながら勉強した
- 用語集作る感じで勉強するのがいいよね、という同僚のアドバイスを早めにもらったのが、本当助かりました
- 辛みを分かち合いながらやれるのも、救いになりました
- 有料研修の模試がすごく助かった
- 初めてやったとき、全然時間が足りなくて正答率が低く、絶望したのが幸いしました。これはまずいぞ、と
- GPTに課金
- ごめん、分からん。が多くて、GPTに相当お世話になりました
- 同僚達と情報交換しながら勉強した
- 失敗したなぁ
- いつも思うんだけど、勉強開始するのが遅いんですよtomoさん
- 30回は「これ先週時点でやっておけば〜〜〜〜〜〜〜〜」という後悔を叫びながらやってました。学ばない
- 3日間ぐらいの勉強時間しかなかったので、最後の方、脳内メモリリークしてました。いや、オーバーフローか。メモリ少ないのに勘弁してほしい
- 買った本が古かった
- 有料研修が動画メインだったので、移動中に気軽に読めるように本を買って読んでいたのですが、初版が4年前と少し古く、模試をやったら全然本に書いてない内容が出てきて「??!」となりました
- いつも思うんだけど、勉強開始するのが遅いんですよtomoさん
G検定受かったらE資格も受かるか
受かりません。E資格に必要なのは、統計学とプログラミングです
全然別物です。もちろん、E試験を受ける前提知識としては必要かなとは思います
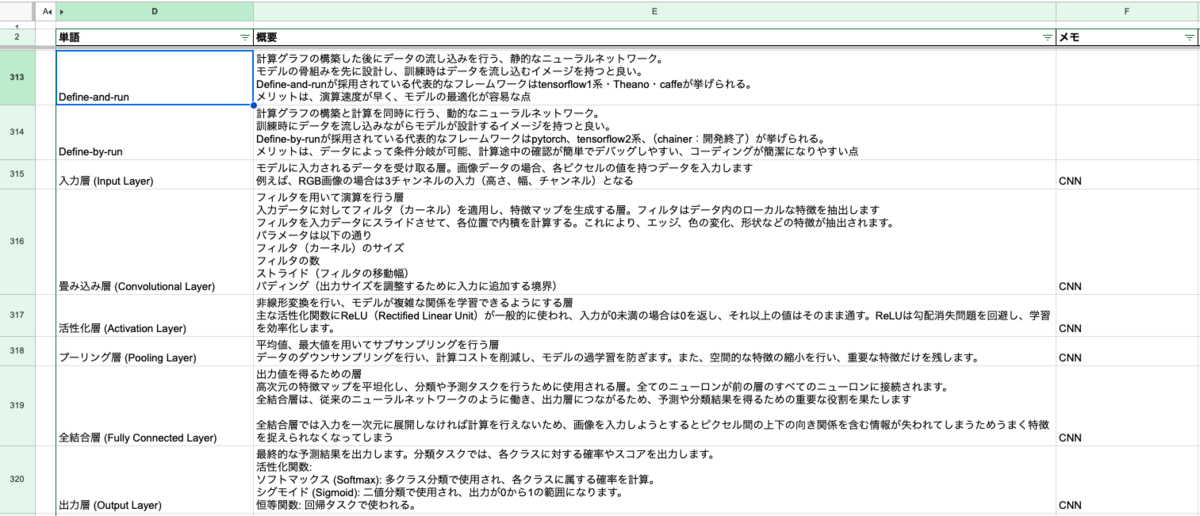
作った用語集
こんなのをスプシで作りました。ツールはお好みで
GPTの回答貼り付けてあったり、模試の解答メモしたりしたので、自分しかわからない、ぐちゃぐちゃな感じを分かって貰えれば
ChatGPTとのやりとり
こんな感じで、まず聞きたいことを聞いて、そこから深堀りしたり、じゃあこれは?なんて聞いたり

最後に感想
受けてよかったか?と聞かれると、もちろん良かったです。
仕組みを知っていて使うのとそうでないのだと、見方が変わりました。
それにAIに何ができて何が苦手で、どう使うのがいいのかとか、こうゆう使い方は良くない(倫理的にも含め)をきちんと学ぶというのは、良い機会だったと思います。
ただ、普段使っていない技術に関する勉強はやはり、ハードル高いなぁとしみじみ。
一緒に受けた同僚達と、今度お祝い飲み会をします。
題して「おれたちジェネラリストになったんだ会」。
なんかジェネラリストって響きがいいですよねぇ